Всех приветствую! Сегодня я вам расскажу как добавить мета тег (noindex, pofollow) и как избавиться от дублей страниц в Вордпресс. Вы же не ждете той минуты, когда вам вдруг скажут, что ваш блог обречен и его ждет провал? Тогда читайте пост очень внимательно.
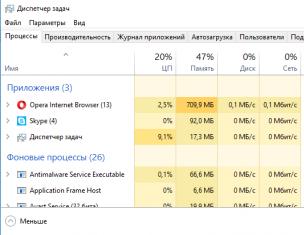
C проблемой дублей я столкнулась сама, когда на моем блоге количество статей перевалило за цифру 10. На блоге стали появляться дубли страниц. Чтобы проверить свой блог на дубли, зайдите в аддурилку Гугл в раздел «Оптимизация HTML».

Это сейчас у меня (смотрите скриншот) два повторяющихся заголовка, потому что я не так давно изменила адрес поста. О том как его изменить можно прочитать в разделе «Дополнительные возможности». В то время когда я забила тревогу у меня было 11 дублей, а потом и 15.
В панике я отправилась на поиски необходимой информации и нашла много советов. Вот один из них: в файле robots.txt пропишите строку — Disallow: /page/ и с этого момента будет индексироваться только главная страница с анонсами статей. Стоит ли закрывать pade в ? Этот вопрос волнует многих и обсуждается на форумах.

Не буду однозначно говорить о том, что этот метод хорош или о том, что этот метод бесполезен. Скажу одно — мне он не помог. Даже после того, как я прописала в robots.txt строку запрещающую индексирование page, количество записей с одинаковыми заголовками только прибавлялись.
Дело все в GOOGLE! Он не обращает внимание на запреты в файле robots.
Чем больше статей вы публикуете, тем больше дублей главных страниц у вас будет.

За дубли страниц поисковые системы нас рано или поздно накажут, поэтому приступим к закрытию подстраниц архивов в noindex.
Вот такую строчку нам надо будет прописать.
Чтобы разместить данный тег можно воспользоваться двумя способами.
Первый способ
Воспользуемся помощью плагина WordPress Seo by Yoast, о том как его установить и настроить я писала . Сейчас я вам напомню, о чем шла речь в моей статье.
Для этого переходим в админку сайта в раздел «SEO» — «Заголовки и метаданные», переходим на вкладку «Остальное» и видим, что у нас стоит галочка напротив Noindex для подстраниц и архивов.

Если мы уберем эту галочку, почистим и перейдем на вторую страницу нашего блога, то в коде страницы увидим, что мета тег pofollow исчез и остался только на ссылках. Если мы снова поставим галочку, то увидим, что мета тег появился снова.
Существует еще один способ и сейчас мы его с вами рассмотрим.
Для тех кто использует другой плагин для seo — оптимизации, можно воспользоваться вторым способом.
Второй способ
Сейчас нам необходимо скопировать код:
function my_meta_noindex () {
if (is_paged()){
echo «».».»\n»;
}
}add_action(‘wp_head’, ‘my_meta_noindex’, 3);
По FTP подключаемся к серверу и в папке с вашей темой находим файл functions.php. Вставляем скопированный тег в свободное место.
Если мы сейчас отключим галочку в плагине WordPress Seo by Yoast, почистим кэш и просмотрим код второй страницы, то данный код отобразится в заголовке нашего сайта.
Я предпочитаю, чтобы все настройки моего блога находились в одном месте, поэтому этот код я удаляю, а буду закрывать подстраницы архивов первым способом с помощью плагина.
Бейте тревогу, если на вашем сайте всего 20-30 статей, а в индексе более двухсот. Скорее всего у вас есть дубли. У меня сейчас нет желания продать вам какой-то инфопродукт или похвалиться своими достижениями. Сегодня моя цель рассказать вам о важных моментах сайтостроительства.
Воспользуйтесь одним из выше перечисленных способов и в скором будущем, если у вас есть дубли главной страницы, количество проиндексированных страниц будет намного меньше. В этом случае такой спад только к лучшему.
Воспользуйтесь советами и забудьте про дубли, не забывайте закрывать от индексации. Чтобы подписаться на обновление перейдите по . Анекдот сегодня будет в видеоформате. До скорых встреч! .
Анекдот:
Мощь? Ну тогда получите еще одну! Не менее мощную. Кучу дублей replytocom вы нашли, это хорошо!
Вот сегодня найдете еще кучу других дублей, которые так же убивают, отравляют ваш блог и плодятся эти дубли все быстрее и быстрее с каждым днем...
Вообще! То что я сейчас расскажу в этой статье это фишки взятые из курса и по идее я не хотел писать эту статью, выставляя ее на всеобщее обозрение. Как говориться, не хотел палить тему. НО! Посидев, подумав, я пришел к выводу, что это просто необходимо сделать.
Почему? А потому что после статьи про дубли replytocom я увидел, что многие начали тупо копировать мой файл robots.txt и думать, что теперь у них все будет в шоколаде. Смотреть на это просто так я не могу, так что приходится вот этой статьей спасать тех засранцев, которые скопировали мой роботс даже ни о чем не думая.
Ну да ладно, в курсе 3.0 есть и так много интересных и полезных фишек. Все естественно на блоге этом спалены никогда не будут.
Итак ок! Поехали. Вспоминаем идею моей прошлой статьи про дубли replytocom. Идея заключается в том, что не надо закрывать в robots.txt доступ к чему либо на блоге. Мы наоборот все открываем, мол, — «Привет робот заходи, все смотри», он приходит и видит метатег:
Таким образом он уже не будет брать страницу в сопли. А если в роботсе будет закрыто, то возьмет все равно на всякий пожарный. =) По количеству комментариев к прошлой статье я понял, что многие ни чего не поняли. было куча вопросов и про robots и про плагин и про редирект и т.д.
Короче ребята, вот тут все ответы на ваши вопросы. Посмотрите это видео перед тем, как читать статью дальше.
Гут! Теперь вспоминаем как мы находили дубли replytocom в выдаче google! Вот так:
site:site.ru replytocom
Как найти дубли страниц на wordpress?
Ок, теперь давайте будем искать другие дубли страниц. А именно дубли:
feed
tag
page
comment-page
attachment
attachment_id
category
trackback
Искать их так же как и replytocom. Снова давайте я поиздеваюсь над уже не просто легендарным, а легендарнейшим Александром Быкадоровым . Захожу в google и вбиваю вот так:
Жму - «Показать скрытые результаты» и вижу вот что:

490 дублей страниц. Feed — это отростки на конце url статей. В любой вашей статье нажмите ctr + u и в исходном коде увидите ссылку с feed на конце. Короче от них надо тоже избавляться. Вопрос — как? Что нам все рекомендуют делать в интернете? Правильно, добавлять что-то подобное в robots.txt:
Disallow: */*/feed/*/
Disallow: */feed
Но если мы посмотрим на блоги, то у всех есть feed в выдаче google. Ну так получается не работает запрет в Роботсе верно? Как тогда от них избавляться? Очень просто — открытием feed в robots.txt + редирект. Об этом дальше.
Хорошо! Это мы проверили только дубли страниц feed, а давайте еще другие проверим. В общем набирайте вот так в google:
site:site.ru feed
site:site.ru tag
site:site.ru attachment
site:site.ru attachment_id
site:site.ru page
site:site.ru category
site:site.ru comment-page
site:site.ru trackback
Все как обычно! Сначала вбиваем, потом идем в конце и нажимаем «показать скрытые результаты» . Вот что я вижу у Александра:




Ну дублей tag, comment-page и trackback у Саши я не нашел. Ну как вы свои блоги проверили? У вас сейчас случайно не такое же лицо, которое я показал в прошлой статье в конце (см. фото)? Если такое, то печально. Ну ни чего, сейчас все поправим.
Как избавиться от дублей страниц?
Итак! Что надо сделать? Первым делом берем вот этот файл robots.txt и ставим его себе:
User-agent: * Disallow: /wp-includes Disallow: /wp-feed Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Host: site.ru Sitemap: http://site.ru/sitemap.xml User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
Только не забудьте site.ru заменить на ваш блог. Так, ок. Роботс поставили. То есть открыли все, что было закрыто. А у многих закрыто было многое и category и tag и feed и page и comment и т.д. и т.п. Теперь нам надо на страницах дублей где есть возможность поставить метатег noindex тот самый:
А где этой возможности нет, там ставим редирект со страницы дубля на основную страницу. Сейчас чтобы вы не сошли с ума о того, что я тут буду рассказывать, лучше сделайте следующее:
Шаг №1: Добавьте вот эти строки в свой файл.htaccess:
RewriteRule (.+)/feed /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/trackback /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/attachment /$1 RewriteCond %{QUERY_STRING} ^attachment_id= RewriteRule (.*) $1?
Файл этот лежит у вас в корне блога где и папки wp-admin, wp-content и т.д. Вот качните его на пк, откройте блокнотиком и добавьте. Вот так все должно примерно быть:
# BEGIN WordPress RewriteEngine On RewriteBase / RewriteCond %{QUERY_STRING} ^replytocom= RewriteRule (.*) $1? RewriteRule (.+)/feed /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/trackback /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/attachment /$1 RewriteCond %{QUERY_STRING} ^attachment_id= RewriteRule (.*) $1? RewriteRule ^index\.php$ - [L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_FILENAME} !-d RewriteRule . /index.php [L] # END WordPress
Шаг №2: Вот этот код добавьте в файл function.php сразу в начале после
/*** ДОБАВЛЯЕМ meta robots noindex,nofollow ДЛЯ СТРАНИЦ ***/ function my_meta_noindex () { if (is_paged() // Все и любые страницы пагинации) {echo ""." "."\n";} } add_action("wp_head", "my_meta_noindex", 3); // добавляем свой noindex,nofollow в head
Шаг №3: Заходим в плагин All in One Seo Pack и ставим вот так:

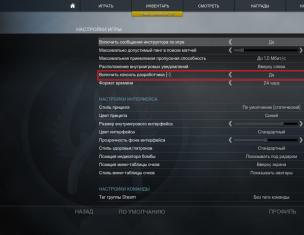
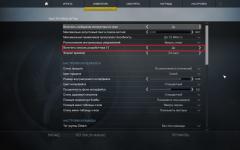
Шаг №4: Заходим в админку — Настройки — Обсуждения и убираем галочку с "Разбивать комментарии верхнего уровня на страницы":

Окей. Это все. Теперь надо ждать переиндексации, чтобы все дубли опять же вылетели из выдачи.
Что мы сделали? Повторю, в robots.txt мы все открыли, о есть теперь робот будет заходить беспрепятственно. Далее на таких страницах как page, tag и category он будет видеть тот самый запрещающий метатег noindex и соответственно не будет брать страницу в выдачу.
На страницы page мы добавили метатег руками вот тем кодом, который вы вставили в файл function.php из шага №2, а страницы tag и category закрылись метатегом благодаря тому, что в плагине All in One Seo Pack мы поставили галочки там где надо, как я показал в шаге №3.
На страницах feed, attachment, attachment_id, comment-page и trackback этот метатег мы не ставили, мы поставили 301 редирект добавлением нескольких строк в.htaccess, что я вам дал в шаге №1.
В админке в настройках обсуждения мы сняли галочку, чтобы у нас комментарии не разбивались на страницы и не создавали новые url.
В общем теперь робот приходя на эти страницы (feed, attachment, attachment_id, trackback), будет автоматически перебрасываться на основные страницы и как правило, дублированные не забирать в выдачу. Редирект — сила! Ну вот собственно и все.
Если вы будете использовать эту схему, то дублей у вас не будет. Схема рабочая и проверена. Кстати пользуясь случаем хочу немного похвастаться. Вот что у меня было по проиндексированным страницам в вебмастере google в апреле:

А вот что сейчас:

А вот что по трафику с Google:

Как видите дублей все меньше становится и трафик все выше и выше. Короче все работает! Честно говоря так обидно, что аж 2 года сидел с этими дублями, не знал про них вообще, как от них избавиться и как следствие сидел на 140-150 посетителях в сутки с google. =))
Кстати трафик с Яндекса тоже заметен уже.
Естественно не все сразу. Жду год. Поставил себе такой срок. Уверен, что за год все дубли уйдут. Вот за 2 месяца ушло более 7200. А как обстоят дела у вас? =) Мне тут уже люди пишут кстати, поставили мою схему и посещалка вверх пошла.
Ребята, схема понятна? Если что вот еще видео специально записал, посмотрите, может быть тут я объяснил по понятнее:
На этом тему дублированного контента на блоге я заканчиваю. Что еще не сказал. Мы с вами рассмотрели нахождение только, так скажем, официальных =))) дублей. Есть еще кроме дублей — шлак и прочий мусор. Его тоже нужно уметь находить и удалять. Вот например некоторые мусорные страницы блога Александра Быкадорова:

И таких вот кривых соплей может быть очень и очень много! У кого-то их тысячи. Как находить этот мусор и много еще чего интересного, я рассказывал в курсе Как стать блоггером тысячником 3.0 . Сегодня последний день цена 2370 и 2570, завтра будет 3170 и 3470.
Помните — хороший сайт — это сайт, на который пришел робот, загрузил главную страницу index, все стальные страницы вашего блога типа «Об авторе», «Контакты»..., и все ваши статьи! Все, больше ни чего в выдачу забирать он не должен. Если забирает, но это печально и плохо.
В заключение статьи хотелось бы поблагодарить Сашу Алаева , мега супер-пупер крутого SEOшника, за помощь в создании и robots.txt и.htaccess. Эти рекомендации и не только эти, очень помогли мне в написании этих двух статей про дубли, а так же в создании курса КСБТ 3.0.
Ну все! Напишите в комментариях кто сколько у себя дублей нашел! =) Может быть у вас еще есть какие-то дубли в выдаче? Можно попробовать разобраться в их устранении!
P.S. Давайте поржем еще раз в завершении. Вот лицо человека, который через несколько лет ведения блога узнал, что у него куча дублей и мусора в выдаче:

Всем пока и удачных выходных!
С уважением, Александр Борисов
Table of Contents
Что такое дубли страниц?
Очень часто владельцы wordpress сайтов начинают беспокоиться, если не понимают из-за чего отдельные страницы проваливаются в выдаче. Причиной тому могут быть дубли страниц. Это страницы, содержащие материалы с идентичным или похожим контентом. Речь о страницах архивов дат, рубрик, авторов и комментариев. При этом они могут располагаться под разными адресами, что позволяет дублям конкурировать с основной статьей за место в поисковой выдаче. В этом материале мы расскажем как избавиться от дублей страниц.
Создание дублей страниц на сайте
Как мы уже рассказывали ранее, дубли одной конкретной страницы, где размещена одна конкретная статья создаются и в архивах дат, и в рубриках или категориях (могут называться по-разному), а также на страницах с комментариями. Благодаря этому пользователи могут сортировать посты и находить по определенным критериям нужные. Система делает это автоматически.
Давайте посмотрим как это выглядит на примере архива дат. Предположим нам нужно выбрать все статьи за ноябрь. На главной странице сайта кликните на ссылку в виджете с указанием месяца.

Дубли в комментариях
При работе с комментариями вебмастерам следует учитывать, что как таковые, дубли страниц создаются при наличии древовидной системы обсуждения. В том числе если обсуждений очень много и комментариям не хватает места на одной странице, то часть их перемещается на следующие. И в этом случае вам необходимо удалить дубли страниц в wordpress, иначе проиндексированные страницы станут своеобразной ловушкой для пользователей. Они просто попадут на страницу комментариев статьи, а не на саму статью, после чего посетители, скорее всего покинут сайт. SEO-продвижение явно пострадает от большого количества отказов.
Как удалить дубли с помощью плагина WordPress
Чтобы не разбираться с провалами в поисковой выдаче, лучше заранее провести профилактическую работу. А именно удалить дубли страниц в wordpress. Мы предлагаем вам воспользоваться плагином оптимизации сайтов . В его арсенале большой спектр полезных функций для удаления дублей страниц. Скачайте данное приложение и установите, так мы сможем рассказать о всех фичах более предметно.
После активации перейдите в меню настроек плагина: «Настройки» => «Clearfy меню» =>


Начнем по порядку, с удаления архивов дат. Здесь стоит сразу уточнить, что удалять дубли в буквальном смысле мы не будем. Их просто отключат от индексирования. И это важнее, чем избавиться фактически от копий страниц. Если дубликаты не видит поисковик, значит пользователь перейдет на основную, нужную вам для продвижения страницу и не заблудится в многообразии ссылок-клонов. Чтобы запустить функцию нажмите кнопку ВКЛ.


Чтобы удалить метки архивов, нужно поставить редирект со страниц тегов на главную. Для этого активируйте функцию ниже. Аналогично предыдущим. Обратите внимание на серую метку со знаком вопроса. Она указывает на то, что негативных последствий настройка не вызовет.

Для каждой фотографии или видео wordpress создает отдельную «страницу вложений» с возможностью комментирования, что является своеобразным якорем оптимизации. Подробней об этом мы говорили в предыдущей . Нажимаем кнопку ВКЛ.
Если у вас на сайте пагинация настроена таким образом, что контент размещается сразу на нескольких страницах, то в конце URL, в том или ином виде, будет добавляться порядковый номер каждой страницы. Clearfy же, предложит вам удалить постраничную навигацию записей. То есть каждая страница одной статьи будет редиректиться на основную. Нажмите кнопку ВКЛ.
Если у вас настроены древовидные комментарии, то их иерархия создаст благоприятные условия для создания копий страниц. Выглядит это так: вы отвечаете на чей-то комментарий и одновременно в URL появляется переменная?replytocom – это значит, что поисковик видит в этом не ответ на комментарий, а отдельную страницу, так как адрсе отличается. Удалить дубли страниц в wordpress и выполнить редирект вы можете активировав данную функцию.

Заключение
Время и силы, затраченные на продвижение сайта или отдельных статей могут уйти впустую. Если не позаботиться об удалении дублей страниц заранее. Они индексируются поисковиком и могут составить конкуренцию основным статьям. После прочтения данной статьи мы надеемся, что вы оценили весь спектр представленных функций и теперь вам будет несложно удалить дубли страниц в wordpress.
Хочу сделать небольшое добавление ко всему сказанному. Если Вы почитаете в интернете посты некоторых известных блоггеров про то, как убрать дубли в WordPress из поисковой выдачи, то поймете, что разговор выходит довольно длинный , и это действительно так. Даже того, что было проделано в указанных статьях данного блога, недостаточно, чтобы полностью убрать лишний контент из поиска. Т.е. все это работает, но не до конца.
Разобьем сегодняшнюю задачу на части.
- Удаление ненужного заголовка
- Форматирование комментариев
- Работа со страницами с пагинацией
Пройдемся по каждой из них.
Удаление ненужного заголовка
Вот казалось бы, мы пишем новые статьи, отвечаем комментаторам, ставим ссылки на свой блог, прописываем title к картинкам, везде где надо и не надо, но… что-то все равно идет не так, как хотелось бы. Работает все не совсем так, как ожидалось. Гугл нас весело индексирует, думаешь, куда ж он на этот раз впихнет ссылку на проиндексированную страницу… А Яндекс как-то не спешит. Нет, он сам по себе тормознутый неспешный. Может это еще не все?
Так вот было замечено, что автоматически добавляемый к ответу сервера заголовок rel=shortlink Яндекс не любит. Дубль по ней не создается, так как у Вас наверняка прописаны canonical для страниц, да и если вбить ссылку, которая приходит в заголовке (сейчас покажу), в яндексовский сервис «Проверка ответа сервера «, то ответом является 301 Moved Permanently. Видимо, Яндекс воспринимает это как мусор на странице, который ему не нравится.

Мы видим, что заголовок отдается. Но у меня на блоге установлен плагин кэширования , поэтому следующий тычок по кнопке отдает несколько другой набор заголовков, что видно на картинке ниже, так что имейте это ввиду при тестировании.

Чтобы отключить этот заголовок, открываем файл /wp-content / themes / ваша-тема / fuctions.php и пишем перед символами?> всего одну строчку:
remove_action(‘template_redirect’, ‘wp_shortlink_header’, 11);
remove_action (‘template _ redirect’, ‘wp_shortlink _ header’, 11 ) ; |
Сохраняем файл, чистим кэш, если такой плагин у Вас используется, и видим, что заголовок исчез.
Форматирование комментариев
Тут придется поработать побольше, саму проблему стоит разделить на более мелкие кусочки.
- Решение проблемы replytocom
- Что делать с #comment ?
Возьмем с данного блога форму готового комментария и пронумеруем, к чему относятся данные проблемы.

Преобразование ссылки на сайт комментатора в тег span
Несмотря на то, что все URL сайтов комментаторов по умолчанию снабжены атрибутом rel=’external nofollow’, держать открытыми данные URL не есть гуд. Но убирать их совсем тоже нет никакого смысла, поскольку добрую часть ценных комментаторов с блога Вы уберете.
Не будем скрывать, что многие блоггеры оставляют комментарии на других блогах не только для того, чтобы просто оставить отзыв о работе, проделанной автором статьи, но и чтобы на том сайте появилась ссылочка на блог комментатора, по которой можно тыкнуть
. Иными словами, комментатор привлекает на свой блог других людей с Вашего сайта. Увы, не будет и такой возможности, скорее всего, и комментариев почти не будет. Поэтому мы оставим возможность перейти на сайт комментатора, но саму ссылку « Напомню, что у меня шаблон Reverie, необязательно, что код, приведенный ниже, непременно подойдет Вам, нужно лишь понять смысл происходящего . Открываем все тот же файл fuctions.php Вашей темы и перед тегом?> пишем: function remove_tag_a_link($tag_remove) {
$url = get_comment_author_url($comment_ID);
$cut = array(" function
remove_tag_a_link
($
tag
_
remove)
{
$
url
=
get_comment_author_url
($
comment
_
ID)
;
$
cut
=
array
(" $
insert
=
array
(",
" return
str_replace
($
cut
,
$
insert
,
$
tag_remove
)
;
add_filter
("get_comment_author_link"
,
"remove_tag_a_link"
,
"url"
)
;
Данный код элементы одного массива ($cut) заменяет элементами другого массива ($insert). Везде в интернете Вы найдете данный код, в котором в каждом из этих массивов 4 элемента, то есть последний заменяемый элемент в ссылке на сайт комментатора был rel=’external nofollow’. Но дело в том, что в моем шаблоне в теге « Честно говоря, мне тут и добавить нечего, просто дам ссылку на , где подробно описано, как сделать так, чтобы при щелчке на «Ответить» форма ответа выводилась скриптом, встроенным в WordPress, а сам этот элемент страницы перестал быть ссылкой. Если этого не сделать, то мы получаем в поисковых системах кучу дублей replytocom
. И все наши труды по продвижению блога будут выброшены. Поисковики дубли все-таки не любят. Лично я использовала метод добавления функции в файл functions.php, так что можете нажать сочетание клавиш Ctrl + F на странице блога SEO Маяк, скопировать туда имя этого файла, первое его упоминание на странице блога как раз встречается в нужном нам абзаце . Если Вы наведете курсор мыши на дату выпуска комментария, он изображен на рисунке выше, то увидите, что это ссылка, имеющая вид http://наш_сайт/… /#comment-230. И сколько есть комментариев, столько подобных ссылок у Вас будет. Что же с ними делать, скажете Вы?! Ответ: ничего
! Ничего, так как с точки зрения поисковых систем это не дубли, это якори для улучшения навигации по странице. Конечно, если Вы очень захотите, Вы можете удалить эту ссылку, но делать это совсем не обязательно, пусть будет . Если картинки, на которые были постоянные ссылки, все же попали в индекс поисковых систем, то они оттуда нескоро пропадут. По моему опыту, если прописать 301 редирект на них, они начнут массово исчезать из индекса примерно через месяц-два. Раньше ждать чудес не стоит. В статье про удаление постоянных ссылок на картинки я приводила некий скрипт, в котором были прописаны редиректы для страниц с картинками. Когда я стала смотреть ответ сервера на некоторые, все же проскочившие в индекс гугла, страницы с картинками, то обнаружила, что некоторые из них отдают 302 редирект. Такие страницы могут висеть очень долго, так как поисковая система надеется, что может быть страничка еще «очухается», так как недаром данный редирект носит название «временный». Поэтому открываем файл /wp-content / plugins / attachment-pages-redirect / attachment-pages-redirect.php и, если мы столкнулись с подобной ситуацией, просто меняем в функции sar_attachment_redirect строчку wp_redirect(get_bloginfo("wpurl"), 302); Приветствую всех читателей блога! Сегодня я расскажу, как за дубли страниц на wordpress блоге, часто попадают по или БАН, начинающие владельцы сайтов, выбравшие эту sms для своего блога. В этом посте, Вы узнаете, как убрать дубли страниц с помощью файла robots.txt из индекса Яндекс и Google. Но сначала я кратко расскажу о том, почему появляются дубли страниц на сайте, а затем, как решить эту проблему. Если предисловие читать не хотите, то можете сразу перейти ко второй части статьи. Самый распространённый движок wordpress, выбирают большинство пользователей для своих сайтов за его простоту, надёжность и богатый внутренний функционал. Но вместе с этой простотой, на wordpress, есть несколько недостатков, которые «недостатками» являются только для начинающих пользователей, до конца не изучивших все возможности и недостатки этой платформы. Поэтому для всех, кто не знает, поясняю, что wordpress имеет технические свойства генерировать много дубликатов одних и тех же статей, каждая из которых, находится в категориях, метках, архивах по месяцам и по авторам. Дублируются ещё и странички из поисковой формы блога и пагинации, новостной ленты новостей RSS и дубли страниц комментариев. Ничего не подозревающие пользователи, создавали сайт на этом движке, начинали наполнять его контентом и через некоторое, время обнаруживали, что их интернет ресурс, наказан и в поиске, осталось от 1 до 9 страниц. Появление дубликатов страниц, поисковые алгоритмы расценили, как сайт, создающийся для торговли ссылками. Хотя, при этом, он ни в каких ссылочных биржах участвовал, то есть не продавал и не покупал ссылки с сайта и на сайт. Совет 1
На самом деле ответ на вопрос, как убрать дубли страниц, простой. Для этого в файле robots.txt, нужно запретить индексацию того, чего не нужно «скармливать» в индекс ПС (смотрите список ниже). Вот и всё! Как составить файл robots.txt я рассказывал в статье, ссылку на которую только что указал. Там же, Вы узнаете, что обозначает каждая строчка, и что мы запрещаем к индексации. Типы дублей страниц:
Из всего этого количества, можно не закрывать для индексации категории. Совет 2
Обязательно нужно настроить редирект с www..ru и наоборот. Прямо сейчас, можете это проверить следующим образом. В строке браузера, наберите адрес сайта с www перед названием домена, то есть www.. Если всё нормально, то домен будет без www. Если у сайта доменов много, то с них делайте редирект на главное зеркало сайта. Совет 3
Если установлен плагин All in One Seo Pack, а он должен быть обязательно установлен, то в настройках, обязательно поставьте галочки в чекбоксе «Канонические URL’ы». Совет 4
Если заметили, что в индексе Google у Вас проиндексировано больше страниц, чем есть на самом деле, то нужно сделать следующее. Заходите в админ панели на вкладку «Параметры», «Обсуждение» и здесь обязательно (настоятельно рекомендую) снимите галочку напротив пункта «Разбивать комментарии верхнего уровня на страницы». Если этого не сделать, то у каждого комментария, будет отдельная страница дубль со своим url адресом (replytocom), которая появляется, при нажатии на кнопку формы комментирования «Ответить», когда включены древовидные комментарии, которые нужно так же отключить. Иначе, сколько будет комментариев у отдельно взятой статьи, столько же и её дублей. Проверить в Google дубли страниц с комментариями, можно введя url адрес своего блога, с приставкой site: перед доменом и replytocom после него. На скриншоте ниже, Вы можете видеть результат проверки моего блога. Как видите, всё в порядке. Надеюсь, что после прочтения этой статьи, Вы знаете, как удалить дубли страниц. А после того, как примените все полученные знания на своём блоге, то если сделали всё так как нужно, то после индексации, кол-во страниц в индексе Google, должно уменьшится. И ещё раз напоминаю, что в wordpress дубли страниц, появляются из за технических особенностей этого движка и появляются только в Google, решить которые я рассказал в Способах 2, 3 и 4.
Решение проблемы дублей replytocom
Что делать с #comment ?

Маленькая правка редиректа страниц с картинками

Что такое дубли страниц на сайте
Как убрать дубли страниц